Ordering-служба¶
Для кого это: Архитекторы, администраторы ordering-службы, создатели каналов
Этот раздел служит идейным вступлением в ordering, как ordering-службы взаимодействуют с пирами, их роль в транзакционном потоке и обзор доступных в настоящее время реализаций ordering-службы, с фокусом на рекомендованной реализации ordering-службы Raft.
Что такое ordering (упорядочивание)?¶
Многие распределенные блокчейны, такие как Ethereum и Bitcoin, являются permissionless, что означает, что любой узел может участвовать в процессе консенсуса, когда транзакции упорядочиваются и группируются в блоки. Поэтому эти системы полагаются на вероятностные алгоритмы консенсуса, которые гарантируют высокую вероятность синхронизированности реестра, но все еще уязвимы к проблеме расходящихся реестров (проблеме “форков” реестра), когда разные участники сети имеют разные представления принятого порядка транзакций.
Hyperledger Fabric работает по-другому. Он содержит узел, называемый ordering-узлом, который упорядочивает транзакции и в совокупности с другими ordering-узлами формирует ordering- службу. Поскольку архитектура Fabric полагается на детерминированные алгоритмы консенсуса, каждый блок проверенный пиром гарантированно корректен. В Hyperledger Fabric форк реестров не может произойти, как в других распределенных permissionless блокчейн-сетях.
Кроме того разделение процессов подтверждения запуска чейнкодов и упорядочивания делает Fabric более производительной и масштабируемой.
Ordering-узлы и конфигурация канала¶
В дополнение к упорядочивающей роли, ordering-узлы также поддерживают список организаций, имеющих право создавать каналы. Этот список организаций называется консорциум и хранится в конфигурации системного канала. По умолчанию этот список и канал, где он хранится, могут редактироваться только администратором ordering-службы. Заметьте, что ordering-служба может хранить несколько таких списков. Конфигурационные транзакции обрабатываются ordering-службой, поскольку ей нужно знать текущий набор политик для контролирования доступа.
Ordering-узлы также предоставляют базовый контроль доступа для каналов, ограничивая, кто может читать и записывать данные, а также кто может их настраивать. Помните, что на тех, кому разрешено изменять конфигурацию в канале, распространяется политика, установленная соответствующими администраторами при создании консорциума или канала. Конфигурационные транзакции обрабатываются ordering-службой, поскольку она должна знать текущий набор политик для контролирования доступа. В этих случаях ordering-узел обрабатывает обновление конфигурации, чтобы убедиться, что задавший запрос обладает надлежащими администативными правами. Если это так, то ordering-служба проверяет запрос обновления по существующей конфигурации, создает новую конфигурационную транзакцию и упаковывает ее в блок, который передается всем пирам в канале. Пиры обрабатывают конфигурационную транзакцию, чтобы проверить, что изменения, подтвержденные ordering-узлом действительно соответствуют политикам, определенным в канале.
Orderering-узлы и Identity¶
Все, взаимодействующее с блокчейн-сетью, в том числе пиры, приложения, администраторы, ordering-службы, получает identity их организации из определения Membership Service Provider (MSP).
Чтобы узнать больше про identities и MSP, ознакомьтесь с нашей документацией про Identity и Membership.
Также как и пиры ordering-узлы принадлежат организациям. По аналогии с пирами, для каждой организации используются отдельные Certificate Authority (CA), будет ли он корневым или промежуточный, связанный с корнем, зависит от вас.
Orderering-служба и транзакционный поток¶
Первая фаза: Proposal¶
Из темы про пиры мы знаем, что они формируют основу блокчейн-сети, храня реестры, которые приложения через смартконтракты запрашивают или обновляют.
В частности, приложения, которые хотят обновить реестр, участвуют в процессе, состоящем из трех этапов и обеспечивающим всем участникам блокчейн-сети синхронизированность их реестров.
На первом шаге клиентское приложение посылает транзакционное proposal набору пиров, которые запустят смартконтракты для создания предлагаемого обновления реестра и затем подтвердят результаты. Подтверждающие пиры не применяют предложенное обновление к их копии реестра, а возвращают ответ на proposal клиентскому приложению. Подтвержденные ответы будут в конечном счете упорядочены в блоки на втором этапе, а затем распространены среди всех пиров сети для окончательной проверки и сохранения на третьем шаге.
Для более подробного описания первой фазы, ознакомьтесь с темой пиры.
Вторая фаза: Упорядочивание и упаковка транзакций в блоки¶
После завершения первой фазы транзакции клиентское приложение получило подтвержденный ответ на транзакционное proposal от набора пиров. Теперь наступает вторая фаза транзакции.
На этой фазе клиентские приложения передают транзакции, содержащие одобренные ответы на транзакционное proposal ordering-узлу. Ordering-служба создает блоки из транзакций, которые в конечном счете будут распространены среди всех пиров для окончательной проверки и сохранения на третьей фазе.
Узлы ordering-службы одновременно получают транзакции от многих разных клиентских приложений. Узлы ordering-службы работают вместе, в совокупности состовляя ordering-службу. Ее задача заключается в том, чтобы сформировать из представленных им транзакций последовательность и упаковать их в блоки, составляющие блокчейн.
Количество транзакций в блоке зависит от параметров конфигурации канала, связанных с желаемым
размером и максимальной задержкой между блоками (а именно параметров BatchSize и
BatchTimeout). Блоки затем сохраняются в реестр ordering-службы и распространяются всем пирам,
присоединившихся к каналу. Если так получилось, что пир был не в сети или присоединился к каналу
позже, он получить блоки после повторного подключения к узлу ordering-службы или после общения по
gossip протоколу с другим пиром. Посмотрим, как пиры обработают этот блок на третьем этапе.
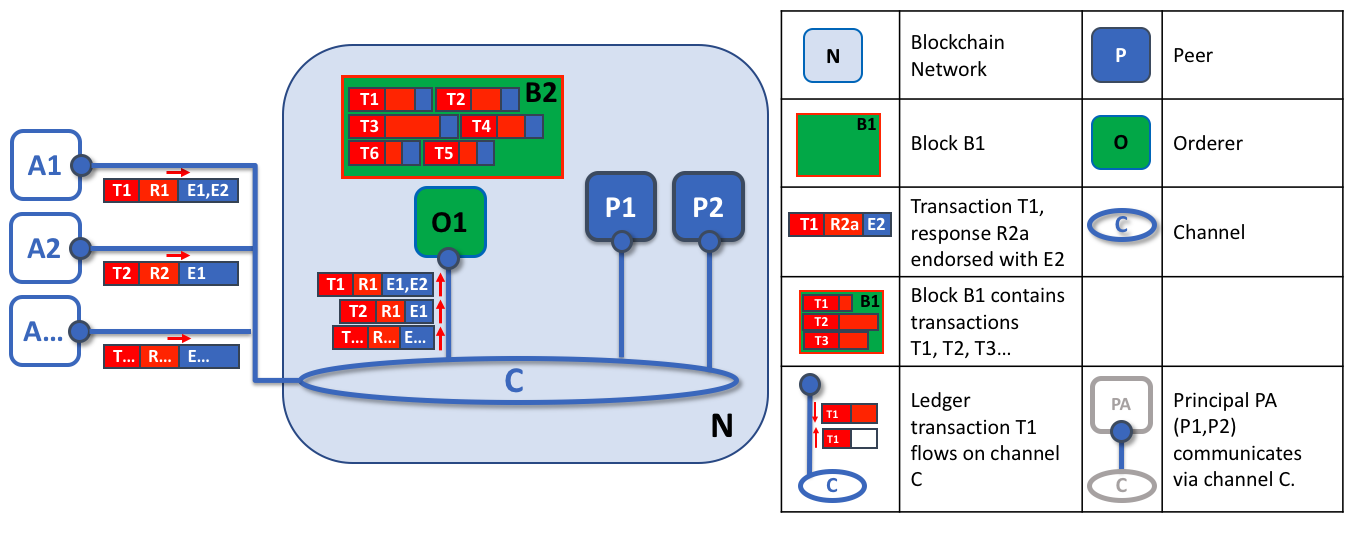
Первой задачей ordering-узла является упаковка предложенных обновлений реестра. В нашем примере приложение A1 посылает транзакцию T1, подтвержденную E1 и E2 ordering-узлу O1. Параллельно приложение A2 посылает транзакцию T2, подтвержденную E1 ordering-узлу O1. O1 упаковывает T1 и T2 вместе с другими транзакциями от других приложений сети в блок B2. Можно видеть, что порядок транзакций в B2 такой: T1,T2,T3,T4,T6,T5 – что не обязательно является порядком, в котором они прибыли в ordering-узел. (Этот пример показыает очень упрощенную конфигурацию ordering-службы с единственным ordering-узлом.)
Важно заметить, что последовательность транзакций в блоке не обязательно упорядочена по времени поступления в ordering-узел, поскольку может быть несколько узлов ordering-службы, которые получают транзакции приблизительно в одно время. Ordering-служба строго упорядочивает транзакции, и именно этот порядок будут использовать пиры при проверке и сохранении транзакций.
Строгий порядок транзакций в блоках отличает Hyperledger Fabric от других блокчейнов, где одни и те же транзакции могут быть упакованы в несколько разных блоков, соревшующиеся за формирование цепи. В Hyperledger Fabric блоки, сгенерированные ordering-службой, являются окончательными. После того, как транзакция записывается в блок, ее позиция в реестре становится неизменяемой. Окончательность Hyperledger Fabric означает, что не появляются форки реестра — проверенные транзакции никогда не аннулируются и не возвращаются.
Мы также можем видеть, что, в отличие от пиров, ordering-узлы не обрабатывают транзакции и не запускают смартконтракты. Каждая транзакция, приходящая к ordering-службе механически упаковывается в блок — ordering-узел не выносит сужденя о содержании транзакции (кроме транзакций конфигурации канала).
Теперь мы знаем, что ordering-узлы ответственны за простые, но жизненно важные процессы сбора предлагаемых обновлений реестра, их упорядочивание и упаковку в блоки, готовые к распространению.
Третья фаза: Проверка и сохранение¶
Третья фаза транзакционного потока состоит из распространения и последующей проверки блоков, после чего их можно сохранять в реестр.
Третья фаза начинается с распространения блоков ordering-узлом всем пирам, подключенным к нему. Важно заметить, что не каждый пир должен быть подключен к ordering-узлу — пиры могут передавать друг другу блоки с использованием gossip-протокола.
Каждый пир независимо проверяет распространенные ему блоки, но проверка детерменирована, поскольку реестр должен оставаться повсюду одинаковым. Говоря конкретнее, каждый пир в канале проверит все транзакции блока, чтобы удостовериться в подтверждении пиров нужных организаций, что их подтверждения совпадают, и что они не утратили валидность после недавно сохраненных транзакций, выполнявшихся во время подтверждения. Аннулированные транзакции сохранены в неизменяемом блоке, созданном ordering-службой, но помечены, как невалидные пирами и не обновляют состояние реестра.
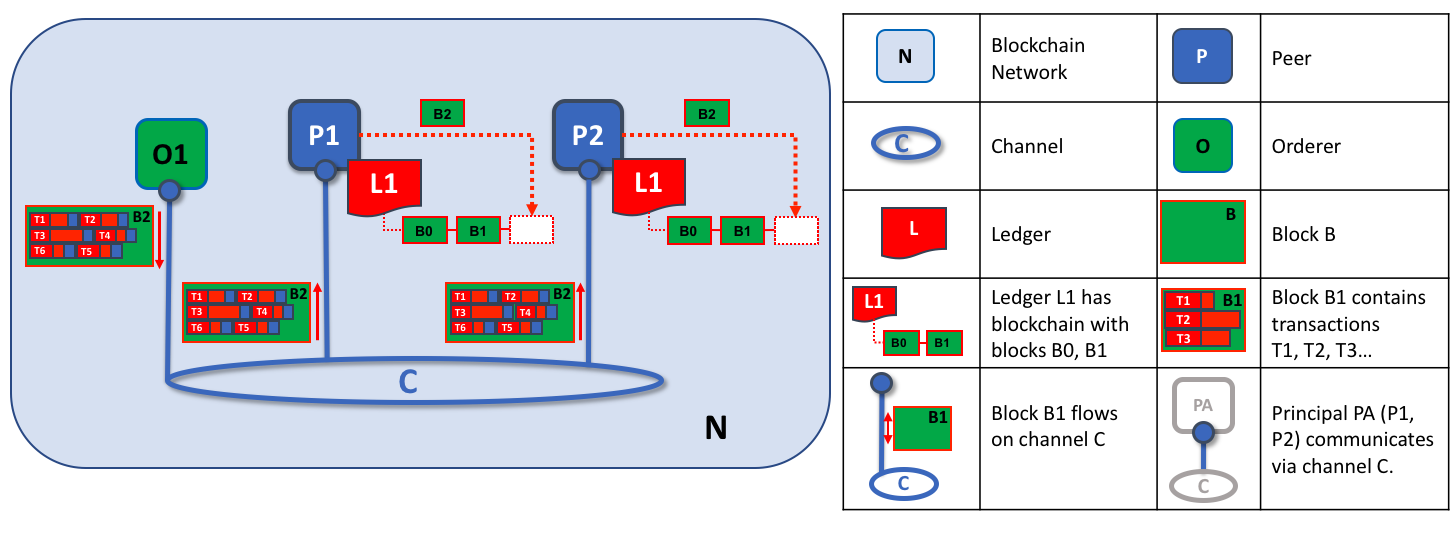
Второй задачей ordering-узла является распространение блоков пирамю В нашем примере ordering- узел O1 распространяет блок B2 пиру P1 и пиру P2. Пир P1 обрабатывает блок B2, добавляет новый блок в свою копию реестра L1. Параллельно пир P2 обрабатывает блок B2, добавляет новый блок в свою копию реестра L1. По завершению процесса реестр L1 обновлен одинаково на обоих пирах P1 и P2, и каждый из них может передать подключенному к нему приложению, что транзакции были обработаны.
По итогу в третьей фазе блоки, созданные ordering-службой, равномерно добавляются в реестр. Строгий порядок транзакций в блоках позволяет каждому пиру проверять, что транзакции обновления равномерно добавляются повсюду в блокчейн-сети.
Для более подробной информации вернитесь к теме про пиров.
Реализации ordering-служб¶
Хотя все доступные ordering-службыы обрабатывают транзакции и обновления конфигураций одинаково, существует несколько реализаций, достигающие консенсуса по строгому порядку транзакций между узлами ordering-службы.
Как развернуть ordering-узел (вне зависимости от реализации) можно узнать в разделе документации, посвященном разворачиванию ordering-узла.
Raft (рекомендовано)
Принятый с v1.4.1, Raft является crash fault tolerant (CFT) (устойчивой с сбоям) ordering- службой, основанной на реализации протокола Raft в
etcd. Raft придерживается модели “лидер и последователь”, где выбранный (в канале) лидер-пир принимает решения, которые повторяют последователи. Ordering- службы Raft проще устанавливаются и управляются, чем ordering-службы Kafka, а их архитектура позволяет разным организациям предоставлять узлы в ordering-службу.Kafka (прекращена поддержка в v2.x)
Также как ordering основанный на Raft, реализация Apache Kafka использует конфигурацию узлов “лидер и последователь”. Ordering-служба Kafka была доступна начиная с Fabric v1.0, однако многие пользователи могут счесть сложности администрирования пугающими и нежелательными.
- Solo (прекращена поддержка в v2.x)
Реализация Solo предназначена только для тестирования и состоит только из одного ordering-узла. Она считается устаревшей и может быть удалена в будущих релизах. Пользователи Solo должны сменить ее на единственный узел Raft для подобных функций.
Raft¶
Обратите внимание на документацию о настройке ordering-службы Raft.
Для промышленных сетей следует выбирать реализацию Fabric протокола Raft. Он использует модель “лидер и последователь”, в которой лидер динамически избирается среди ordering-узлов канала (набор этих узлов называют “consenter set”), и лидер посылает сообщения узлам последователям. Поскольку система выдерживает потерю узлов, в том числе лидеров узлов, пока остается большинство ordering-узлов (также известное как “кворум”), Raft остается “crash fault tolerant” (CFT). Другими словами, если существует хотя бы три узла в канале, он может выдержать потерю одного из них. Если в канале есть пять узлов, то он сможет выдержать потерю двух из них.
С точки зрения сети и канала, существующие ordering-службы Raft и Kafka похожи. Ordering-службы обеих используют архитектуру лидер и последователь. Разработчики же приложений и смарт- контрактов или администраторы пиров не заметят функционального различия ordering-служб Kafka и Raft. Однако существует несколько ключевых отличий, особенно, если вы собираетесь управлять ordering-службами:
- Raft проще установить. Хотя у Kafka есть много поклонников, даже они признают, что развертывание кластера Kafka и его ансамбля ZooKeeper требует высокого уровня знаний о инфраструктуре и настройках Kafka. Кроме того, в Kafka гораздо больше компонент для управления, чем в Raft, из-за чего существует больше мест, где что-то может пойти не так.
- Kafka и Zookeeper не спроектированы для больших сетей. CFT Kafka должен запускаться только в узкой группе узлов. Это означает, что кластер Kafka должен быть размещен у одной организации. Учитывая это, наличие ordering-узлов, управляемых различными организациями, при использовании Kafka мешает децентрализации, потому что все узлы идут к одному и тому же кластеру Kafka, который находится под контролем одной организации. В Raft у каждой организации может быть своя ordering-служба, что делает систему более децентрализованной.
- Raft поддерживается напрямую Hyperledger Fabric, а в случае Kafka и ZooKeeper пользоватлю придется устанавливать и учиться их использовать самостоятельно.
- В то время, как Kafka использует пул серверов (называемых “Kafka brokers”), а администратор ордеринг-службы решает, сколько узлов он хочет использовать в конкретном канале, Raft позволяет пользователям канала указать, какие ордеринг-узлы будут использоваться в канале. Таким образом, организациям не обязательно доверять администратору Kafka-узлов.
- Raft — первый шаг Fabric к BFT ордеринг-службе.
По этим причинам, поддержка Kafka прекращается в Fabric v2.x.
Терминология Raft¶
Хотя внешне Raft имеет много общего с Kafka, его реализация многим отличается и оперирует несколько другими понятиями: записи журнала, Consenter set, Кворум, Лидер, Подписчик.
Роль Raft в транзакционном потоке¶
Каждый канал имеет отдельную копию протокола Raft, что позволяет каждой копии выбирать своего лидера. Такая конфигурация способствует децентрализации службы в сценариях использования, где кластеры собраны из ordering-узлов, контролируемых разными организациями. Все узлы Raft должны быть частью системного канала, однако они не обязательно должны быть частью всех каналов. Создатели каналов (и их администраторы) могут выбирать набор свободных ordering-узлов и добавлять или удалять ordering-узлы (по одному за раз).
Хотя эта конфигурация создает накладные расходы в виде избыточных heartbeat-сообщений и горутин, она предоставляет необходимую для BFT базу.
В Raft транзакции (в виде proposals или обновлений конфигурации) автоматически направляются ordering-узлом текущему лидеру этого канала. Это означает, что пирам и приложениям не нужно знать, кто является лидером в определенное время. Это нужно знать только ordering-узлам.
Когда проверка ordering-службы завершена, транзакции упорядочены, упакованы в блоки, согласованы и распространены в сеть, как описано на шаге два транзакционного потока.
Несколько слов об архитектуре¶
Как в Raft работают выборы лидера¶
Хотя избрание лидера является внутренним процессом ordering-службы, важно понимать, как они работают.
Узлы в Raft находятся в одном из трех состояний: последователь, кандидат или лидер. Все узлы изначально являются последователями. В этом состоянии они могут заносить записи лидера в реестр или голосовать за лидера. Если за определеное время (например, пять секунд) узлы не получают heartbeat-сообщения или новой записи в реестр, то они выдвигают себя в качестве кандидата. В состоянии кандидата, узлы получают голоса других узлов. Если кандидат получает кворум голосов, то он становится лидером. Лидер должен принимать новые записи в реестр и посылать их последователям.
Чтобы визуально представить, как работает процесс выборов, ознакомьтесь с The Secret Lives of Data.
Снапшот¶
Если ordering-узел падает, то как восстановить пропущенные им записи в журнал (лог) при перезапуске?
Хотя хранить все записи в реестр можно бесконечно, чтобы сохранить пространство на диске Raft использует процесс, называемый “снапшотингом”, в ходе которого пользователи могут определять, сколько байт данных будет храниться в журнале (логе). Этот объем данных соответствует определенному числу блоков (а это зависит от объема данных в блоке. Заметьте, что в снапшоте хранятся только целые блоки).
Например, упавшая реплика R1 была повторно подключена к сети. Номер ее последнего блока 100.
Лидер L сейчас на блоке 196, и он настроен делать снапшот каждые 20 блоков. R1 получит
блок 180 от L и пошлет запрос Deliver за блоками от 101 и до 180. Блоки от 180 до
196 будут переданы R1 через обычный протокол Raft.
Kafka¶
Kafka похожа на Raft тем, что использует ту же модель “лидер и подписчик”, в которых транзакции (со стороны Kafka — “сообщения”) копируются подписчиками. Как и в Raft, когда лидер становится недоступным, один из подписчиков становится новым лидером.
Ансамбль ZooKeeper управляет кластером Kafka, что включает в себя распределение задач между узлами, состав кластера, контроль доступа и т.д.
Кластеры Kafka и ансамбли ZooKeeper довольно сложно настроить, поэтому если вы решите использовать Kafka без предварительных знаний о Kafka и ZooKeeper, вы как минимум должны ознакомиться с Kafka Quickstart guide. Также будет полезно ознакомиться со стандартными настройками Kafka и ZooKeeper в качестве ордеринг-службы: пример конфигурации.